Generative AI Writing Assistant
Summary
"Our backlog is a nightmare. We need help drafting content faster, but it still has to sound like us."
I built an AI writing assistant that generates on-brand drafts using a fine-tuned language model and structured context from internal documents. The tool improves tone, fluency, and relevance, helping marketing teams draft documents faster without sacrificing voice or strategy.
- Role — Model trainer, pipeline developer, inference architect, UX designer, evaluator
- Tools — Python, Gradio, Hugging Face, Pinecone, Google Colab (Tesla T4 GPU), Unsloth, LLaMA 3.1 8B, LM Studio
This tool demonstrates the feasibility of a brand-aligned writing assistant using open-source technology, with measurable improvements in relevance, fluency, and voice across test scenarios.
I created this project to explore how generative AI could augment human creativity rather than replace it by designing and fine-tuning a writing assistant that honored brand tone, adapted to inputs, and improved draft quality through structured context.
Gallery
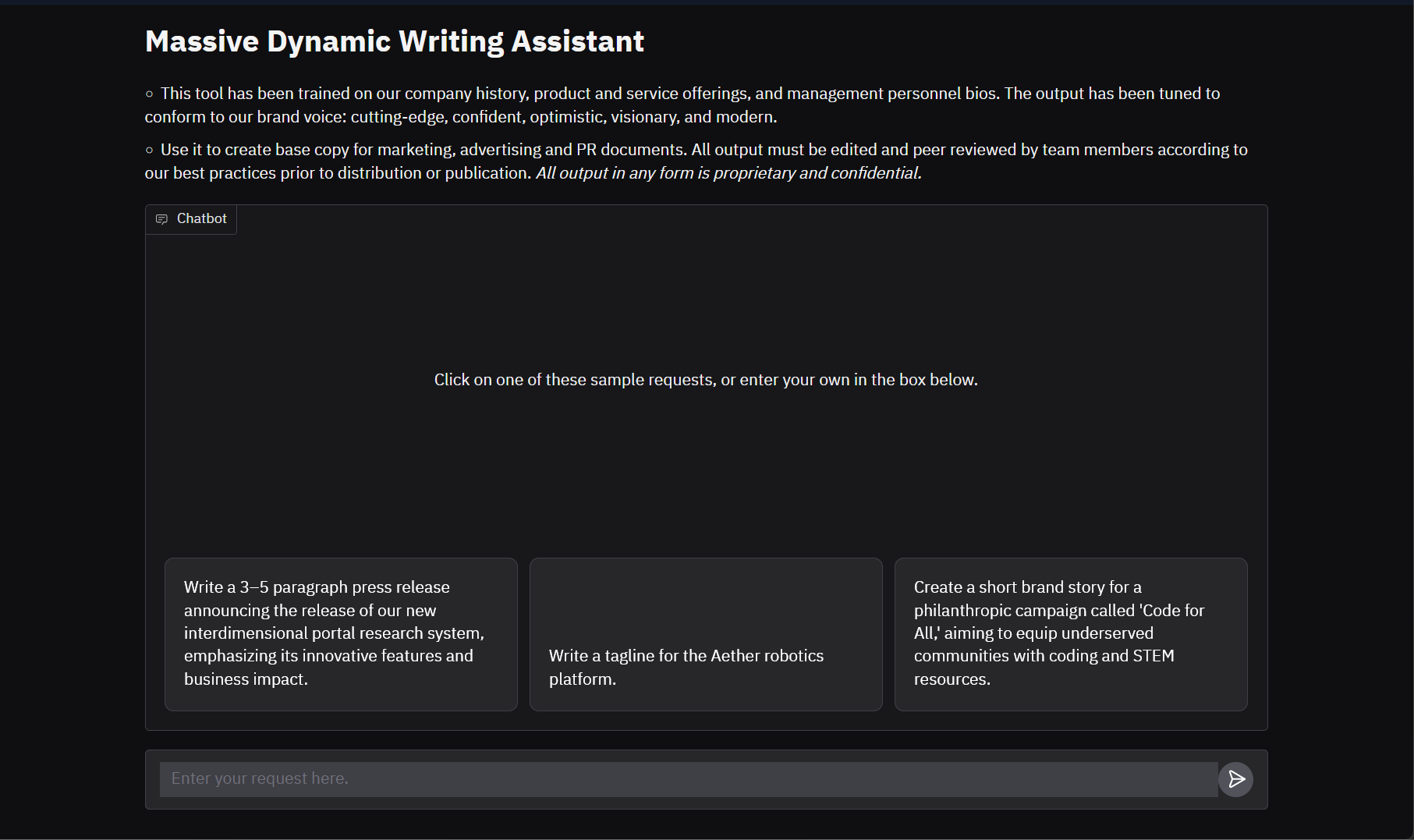
A custom Gradio interface guides users through brand-aligned content creation, including press releases, taglines, and campaign copy, all grounded in fine-tuned tone and fictional company context.

Shown here: a 5-paragraph press release generated using the fine-tuned model and RAG-augmented context, reflecting the brand's confident, visionary voice while preserving structure and clarity.
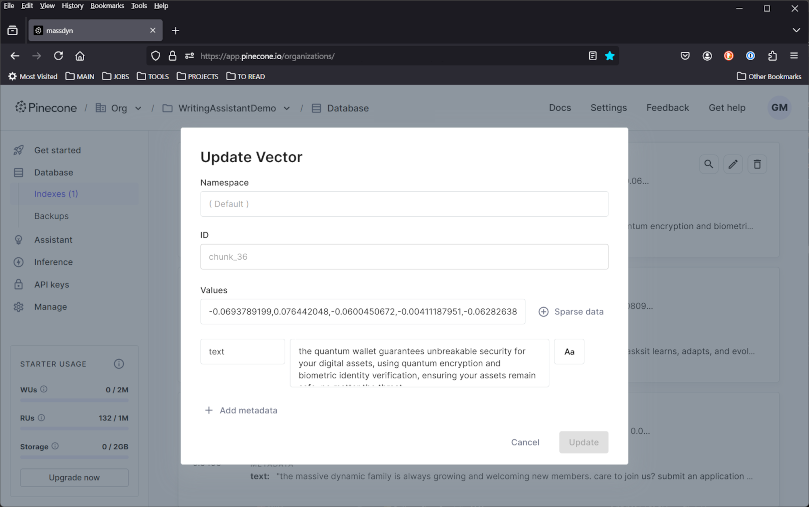
Vectorized company reference material is stored and searchable via Pinecone. Shown here: a chunked embedding for a product blurb, one of many pieces of supplemental context retrieved during user queries.
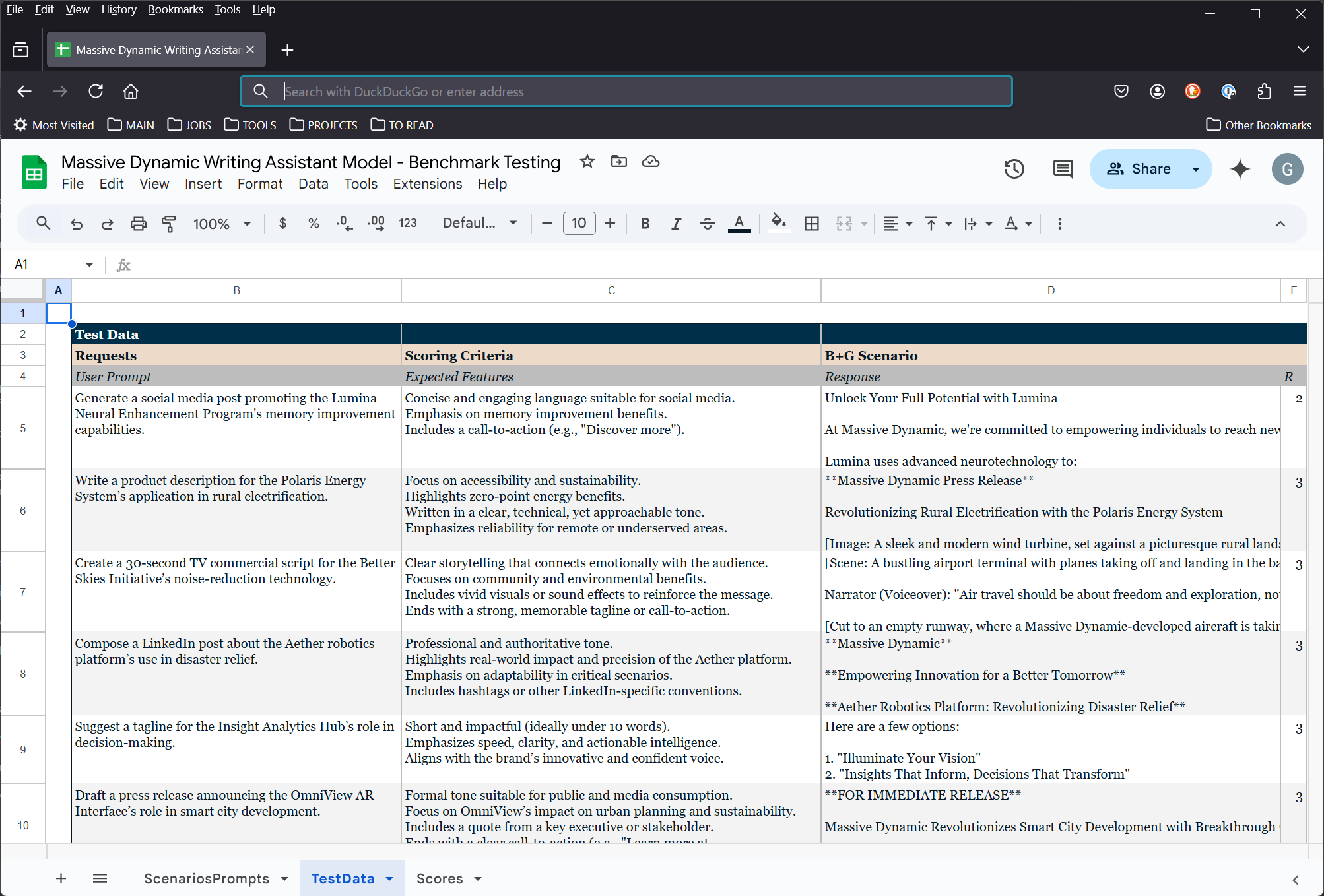
The evaluation framework scored outputs across relevance, brand consistency, fluency, and creativity. Each prompt was tested with and without fine-tuning and brand voice guidance, using a structured rubric for comparison.
Click an image for a closer look and more information.
Details
I broke the project into five key phases, with tooling and decisions tuned for experimentation, iteration, and future portability.
- Defined a five-part brand personality for Massive Dynamic (cutting-edge, confident, optimistic, sleek, mysterious)
- Prompted ChatGPT to generate 300 Alpaca-format entries simulating company documents: memos, ads, social posts, product copy, guides, scripts, etc.
- Validated fictional consistency using known facts from Fringe, while expanding the mythology
- Selected Meta's LLaMA 3.1 8B Instruct model
- Used Unsloth's Colab notebook with modifications to run training on a Tesla T4
- Tuned model in multiple runs, adjusting step count and watching for overfitting
- Exported model in GGUF format with q4_k_m quantization for lightweight inference and local testing
- Supplemented model training with a paragraph-chunked knowledge base (e.g., company fact sheets, historical notes, character bios)
- Cleaned and embedded the content using sentence-transformer embeddings, then stored it in Pinecone
- Chose paragraph chunks over sentence chunks after testing revealed stronger contextual preservation
- Wrote two Python apps using Gradio: one with model-only inference, one with RAG
- Deployed the model to Hugging Face Inference Endpoints using an OpenAI-compatible container
- Built the frontend in Hugging Face Spaces using the more flexible
Blocks APIoverChatInterface - Designed a detailed system prompt to reinforce voice, context rules, disclaimers, and format expectations
To test performance and brand fidelity, I designed a four-scenario evaluation using structured scoring:
- B+G: Base model with general system prompt
- B+BV: Base model with brand voice prompt
- FT+G: Fine-tuned model with general system prompt
- FT+BV: Fine-tuned model with brand voice prompt
Each scenario responded to 10 common prompt types (ads, product blurbs, memos, social posts, etc.) and was scored across four axes:
- R (Relevance): Did it fulfill the prompt?
- C (Consistency): Did it reflect the brand voice?
- F (Fluency): Was the language natural and strong?
- Cr (Creativity): Was the result interesting and original?
- Fine-tuning matters: The fine-tuned model consistently outperformed the base model on fluency and brand consistency
- Paragraph chunking improved RAG quality: Sentence-level chunks returned incoherent or incomplete context
- Quantized GGUF deployment was both portable and performant, outperforming LoRA-injection during inference
Blocks-based Gradio UI allowed for better layout and component control compared toChatInterfaceabstraction- Structured testing enabled meaningful comparisons between scenarios
- Add blind user evaluation to test outputs from a qualitative human lens
- Explore Reinforcement Learning from Human Feedback (RLHF) for ongoing fine-tuning
- Test with real company data to evaluate impact of pretraining conflicts and RAG correction techniques
- Integrate feedback capture in the UI to support live tuning
- Evaluate larger or less-quantized models in enterprise infrastructure
- Fine-tuning and RAG are complementary: training sculpts tone, while RAG grounds factual context
- The choice of chunking strategy and model format can significantly impact output quality
- Even in fictional domains, realism, clarity, and constraints matter for building believable AI assistants
- Lightweight infrastructure (GGUF + Hugging Face Inference + Gradio) is sufficient for production-quality prototypes